There is one gotcha with LIKE predicate, which I recently discovered. It caused me quite a lot of confusion, so I'll describe it here to hopefully save others this headache.
First let's set up a table and fill it with data:
CREATE TABLE T ( [TextColumn] [varchar](100) NOT NULL ) CREATE NONCLUSTERED INDEX [IX_TextColumn] ON T ( [TextColumn] ASC ) ;WITH cte AS ( SELECT a FROM (VALUES('A'),('B'),('C'),('D'),('E'),('F')) x(a)) INSERT INTO T SELECT cte.a FROM cte CROSS JOIN cte cte2 CROSS JOIN cte cte3 CROSS JOIN cte cte4 CROSS JOIN cte cte5 CROSS JOIN cte cte6 CROSS JOIN cte cte7 CROSS JOIN cte cte8 CROSS JOIN cte cte9
DECLARE @v NVARCHAR(4000) = N'C' SELECT COUNT(1) FROM dbo.T WHERE TextColumn LIKE @v
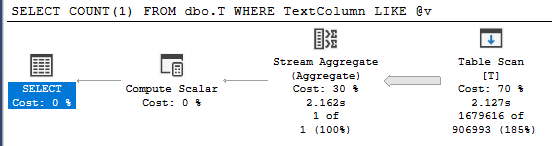
As we see, we've got table scan even though there is perfectly valid index for this query. So why isn't it used? Let's examine the table scan closer:

As we can see there is implicit conversion from NVARCHAR variable to match VARCHAR column. Meaning the predicate is not SARGable. Now that we know the issue there are few possible fixes:
- change the variable to VARCHAR
- add OPTION(RECOMPILE) to the query
- explicitly cast the variable to VARCHAR
In all of the above cases you will end up with nice, quick seek:

Now you may wonder why I found this confusing. There are three reasons:
- Normally when there is implicit conversion happening, the SELECT node has yellow warning mark. The issue is easily noticeable. Not in this case.
- It doesn't happen when you swap the datatypes (column nvarchar, variable varchar)
- The same problem doesn't happen with equality comparison is used:

This issue can become quite problematic when working with NHibernate and probably other frameworks. NHibernate doesn't emit VARCHAR parameters, only NVARCHAR. So if you have VARCHAR columns in your database and you want to filter on them using LIKE keyword you can be unpleasantly surprised performance wise.



